
 Lab1:Stitching substrings into a byte stream
Lab1:Stitching substrings into a byte stream
# Lab1:Stitching substrings into a byte stream
lab1.pdf (cs144.github.io) (opens new window)
在这个 lab 中,我们要实现一个 StreamReassembler。也就是说,在 lab0 实现的 ByteStream 基础上,由于发送的分组可能是失序的,因此我们要将分组重排,以达到 TCP 的按序传送特点。另外,需要注意的是,分组还可能会发生重复等情况。
在 StreamReassembler 中有一个 ByteStream,其用来存放已经顺序的数据,由于 TCP 是累计确认的,因此我们要维护一个从 0 开始的变量 expected_num(与自顶向下书上相同)表示下一个要接受的数据。如果中间有数据失序,也就是 expected_num 的值代表的字节没有被接受到,那么我们就暂停存储数据到 ByteStream,转而将失序的数据缓存,直到前面暂未收到的数据补上了才进一步存储进 ByteStream。上面是大概的思路,接下来我们开始具体实现。
首先,我们先需要明确手册中的 capacity 是什么(一开始理解错了导致写了好久错误代码...)
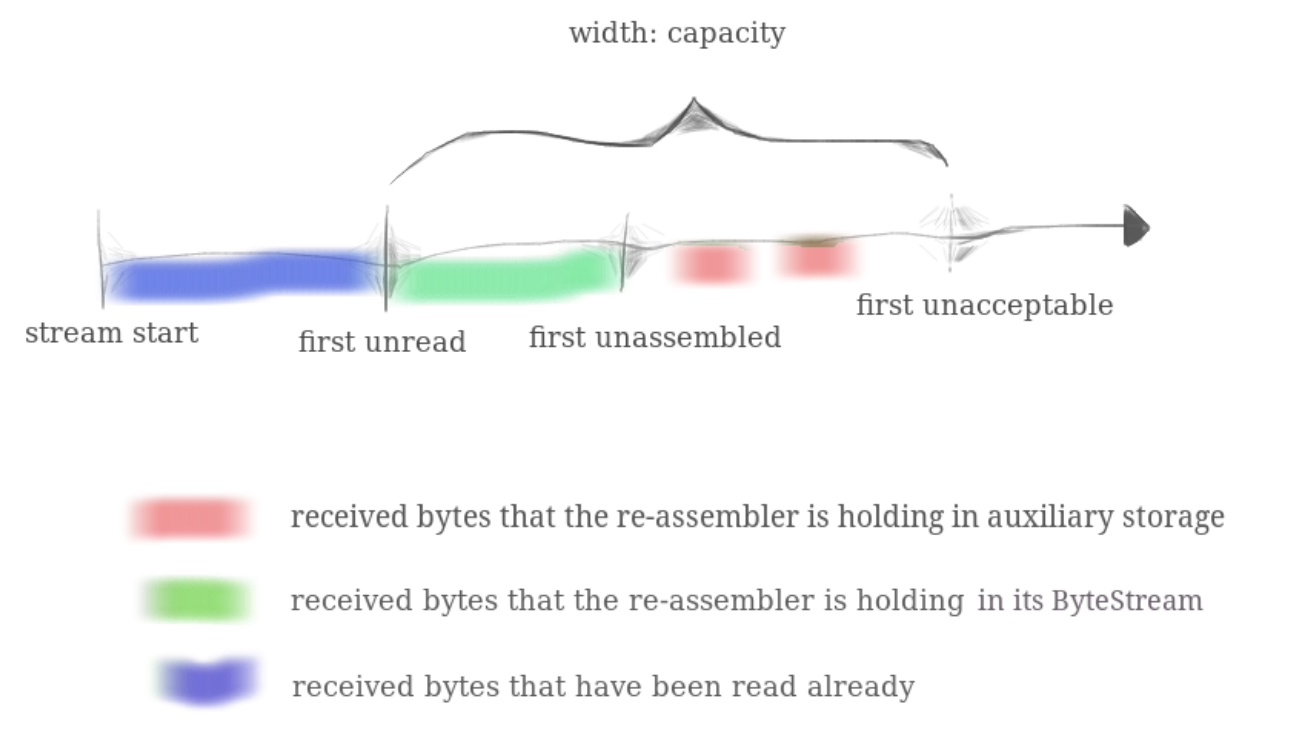
这是一张官方给的图,可以发现我们的 capacity 分配了一部分空间给了 ByteStream,用来存储按序但还未被读取的数据。剩余部分给了 Reassembler 中的辅助数据结构。具体的,假设此时 Reassembler 可用的空间还有
接着,在 Reassembler 中,我们用 unordered_map,也就是哈希表来存储数据(感觉可以多耗费点空间,用双端队列等 DS 来存储,效率会更高)。
最后,代码中还要求我们实现 EOF,也就是说当我们存储到了 EOF 表示的字节后就要调用 lab0 中实现的 end_input() 来关闭写入。我们用两个变量 end_flag、end_num 来实现这一功能。
下面先给出需要定义的 private 成员,作用看注释即可。
private:
// Your code here -- add private members as necessary.
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
// std::set<std::pair<int, std::string>> buf;
std::unordered_map<size_t, char> buf; // Reassembler 存储字节的数据结构
size_t expected_num; // 下一个期望得到的字节序号
bool end_flag; // 是否要求以 EOF 来结束
size_t end_num; // 最后一个数字 + 1 的位置
来到代码实现部分,我们先实现两个比较简单的函数。
未被重排的字节个数就是 buf 的大小,而是否为空直接判断 buf 即可。
size_t StreamReassembler::unassembled_bytes() const {
return buf.size();
}
bool StreamReassembler::empty() const {
return buf.empty();
}
最后是最主要的 push_substring 函数:
开始的时候我们先计算可以在 Reassembler 中存储的最大字节序号 up,那么如过此时 end_flag 已被标记,那么我们的 up 还不能超过 end_num
size_t up = expected_num + _capacity - stream_out().buffer_size();
if (end_flag) {
up = std::min(up, end_num);
}
if (index >= up) return; // 不符合直接 return
接着我们从第一个有效的,即大于 expected_num 的下标开始存储数据
for (size_t i = expected_num > index ? expected_num - index : 0; i < data.size() && index + i < up; i++) {
// if (index + i < expected_num) continue;
buf[index + i] = data[i];
}
那么如果 index 是小于 expected_num 的,那么代表这是一个重复传输的字节,因此我们的起始位置直接从 expected_num - index 开始即可;index + i 表示当前字节的下标。
每次存储完数据之后,我们要看看此时能从 expected_num 开始有序地读入多少个字节,每读完一个还要将其删去,将可读入的字节存放在 s 里,最后将 s 写入 ByteStream。
std::string s;
for (size_t i = expected_num; i < up; i++) {
if (buf.count(i) == 0) break;
s += buf[i];
expected_num += 1;
buf.erase(i);
}
stream_out().write(s);
最后,我们需要对 eof 为 1 的情况特殊处理,打上标记和更新 end_num。另外满足条件的话还要结束输入。
if (eof) {
end_flag = true;
end_num = index + data.size();
}
if (end_flag && expected_num == end_num) {
stream_out().end_input();
}
完整代码:
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
size_t up = expected_num + _capacity - stream_out().buffer_size(); // Reassembler 中能存储的最大字节序号 up
if (end_flag) {
up = std::min(up, end_num);
}
if (index >= up) return; // 不符合直接 return
for (size_t i = expected_num > index ? expected_num - index : 0; i < data.size() && index + i < up; i++) {
// if (index + i < expected_num) continue;
buf[index + i] = data[i];
}
std::string s;
for (size_t i = expected_num; i < up; i++) {
if (buf.count(i) == 0) break;
s += buf[i];
expected_num += 1;
buf.erase(i);
}
stream_out().write(s);
if (eof) {
end_flag = true;
end_num = index + data.size();
}
if (end_flag && expected_num == end_num) {
stream_out().end_input();
}
}
size_t StreamReassembler::unassembled_bytes() const {
return buf.size();
}
bool StreamReassembler::empty() const {
return buf.empty();
}
# 实验结果
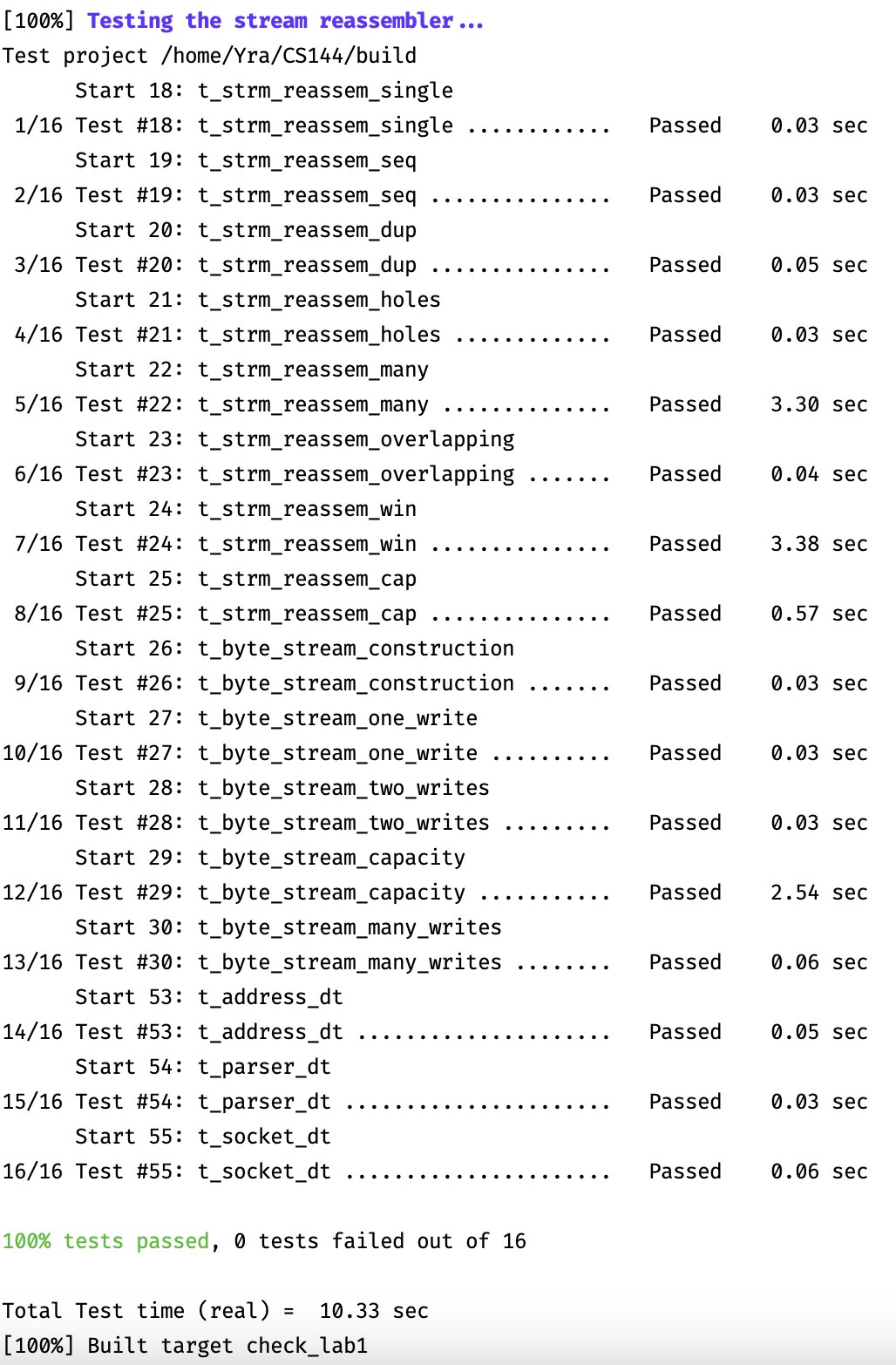
效率一般般,感觉可以用别的数据结构优化一下,但是有点懒了就咕了。