
 「缓存和数据库一致性问题」阅读笔记
「缓存和数据库一致性问题」阅读笔记
本文是在阅读了 『缓存和数据库一致性问题,看这篇就够了』 (opens new window) 后整理的笔记
# 全量缓存(后台定时刷新):
优点: 所有读请求都可以直接命中缓存,性能高
缺点: 缓存利用率低;数据不一致市场依赖于定时时间
# 提高缓存利用率:
- 写请求依然全交给数据库,读请求先访问缓存,不存在则访问数据库并更新缓存,缓存中的数据设置过期时间(只读缓存)
# 数据一致性问题:
「第二步」操作失败引发的数据不一致
先更新缓存,再更新数据库:如果更新数据库失败,会导致缓存中是新值,数据库中是旧值;缓存失效后,都是旧值
先更新数据库,再更新缓存:如果缓存更新失败,数据库中是新值,缓存中是旧值;缓存失效后重读,才变回一致正确
并发引发的一致性问题
假设先更新数据库,再更新缓存:
线程 A 更新数据库 X = 1
线程 B 更新数据库 X = 2
线程 B 更新缓存 X = 2
线程 A 更新缓存 X = 1
数据库中为 X = 2,缓存中 X = 1 ===》 数据不一致
「先更新缓存,更新数据库」的方案类似
解决方案:加 「分布式锁」,但会导致性能下降
「更新数据库 + 更新缓存」 的方案总结
数据不一致问题(「操作失败」和「并发」引起)
性能下降问题原因
引入分布式锁
每次更新可能都要根据数据库中的数据计算缓存中的值(例如计算个人收到的视频点赞数量,可能需要通过计算个人所有视频的点赞数量总和)
缓存利用率低问题原因
- 更新数据库后,无脑更新缓存,但缓存中的数据未必会被马上读取
# 删除缓存方案
『推荐』先更新数据库,后删除缓存
在「第二步」操作失败场景下,数据库中是新值,缓存中是旧值,在缓存失效前会产生数据不一致的问题
在并发场景下,发生数据不一致的概率非常低,「如下面的场景所示」
线程 A 读,线程 B 写,缓存中 X 失效不存在
线程 A 读取数据库得到旧值
线程 B 更新数据库,并删除缓存
线程 A 将旧值写入缓存
数据库中是新值,缓存中是旧值
需要满足:1. 缓存失效 2. 两个线程并发读和写 3. 步骤「2」 比 步骤 「1」「3」 短
写数据库往往要「加锁」,第三点发生概率很低
为了解决「第二步」操作失败场景下的问题,可以采取方案:「重试」
需要考虑的问题有:1. 重试依然可能失败 2. 重试多少次才合理 3. 重试会占用线程资源,无法服务其他客户端请求
更好的方案:「异步重试」
独立出一个消息队列服务,将重试消息发送给该服务,异步化的去更新缓存。
好处:独立服务中的队列,直到消息被成功消费之前都不会丢失,且只有成功消费才会删除
删除缓存的操作还可以通过「订阅数据库变更日志,再操作缓存」,例如阿里的 cannal
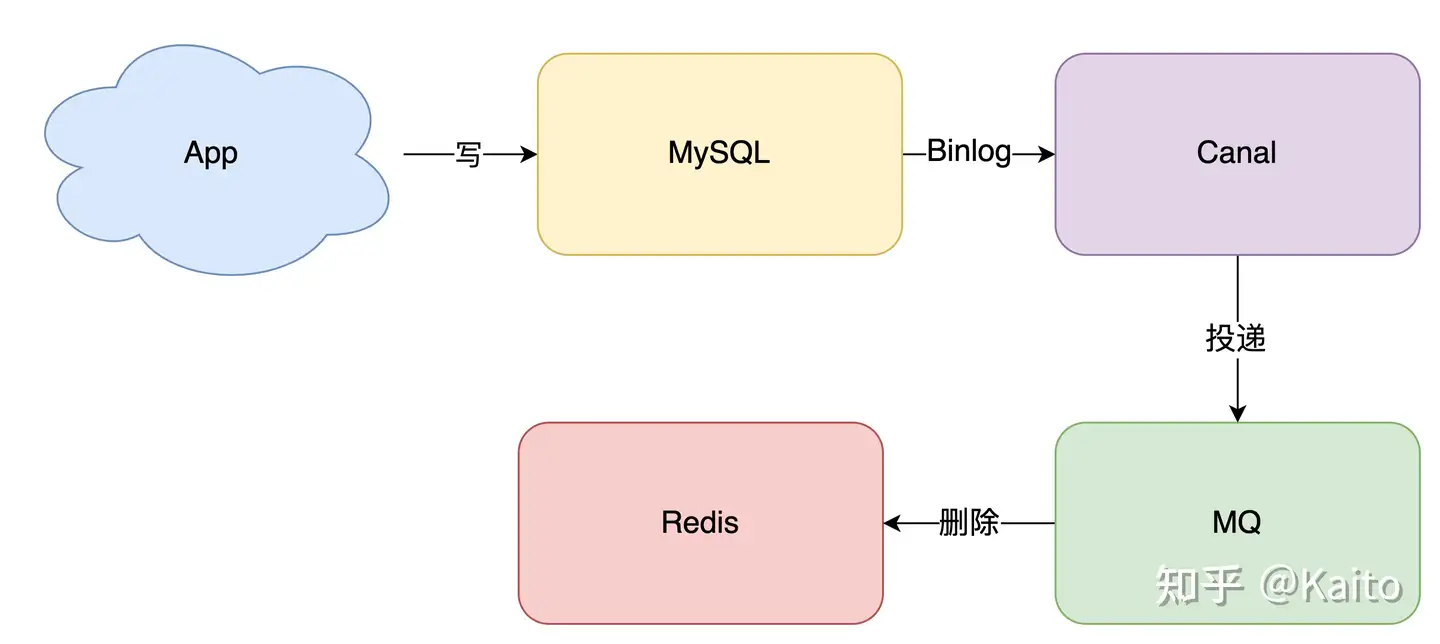
先删除缓存,后更新数据库
在「第二步」操作失败场景下,缓存中没有值,数据库没有更新成功,数据满足一致性
在并发场景下,在下面的情况下会发生数据不一致
线程 A 写,线程 B 读
线程 A 删除缓存
线程 B 读缓存,发生缺失读数据库,得到旧值
线程 A 更新数据库,数据库中是新值
线程 B 将旧值写回缓存
数据库中是新值,缓存中是旧值
# 读写分离 + 主从复制延迟
并发场景下依然会数据不一致,即使采用「先更新数据库,后删除缓存」方案
线程 A 写,线程 B 读
线程 A 删除缓存
线程 B 读取缓存,发生缺失查询从库,得到旧值
从库同步完成,主从库都是新值
线程 B 将旧值写回缓存中
主从库中是新值,缓存是旧值
# 如何解决 ① 「先删除缓存,后更新数据库」 方案 和 ② 「读写分离 + 主从复制延迟」 场景下并发导致的数据不一致问题
「缓存会被回种旧值」是问题的本质
「缓存延迟双删策略」
① 在线程 A 删除缓存,更新数据库 的操作完成后再延迟进行一次缓存删除
② 线程 A 生成一条「延时消息」,写到消息队列中,消费者延时删除缓存
延迟时间设置多久?
延迟时间要大于「主从复制」的延迟时间
延迟时间要大于线程 B 读取数据库 + 旧值写回缓存的时间
在分布式高并发场景下,这个时间很难评估,无法保证极端场景下的数据一致性
# 总结与心得【转载原文内容】
# 总结
1. 想要提高应用的性能,可以引入「缓存」来解决
2. 引入缓存后,需要考虑缓存和数据库一致性问题,可选的方案有:「更新数据库 + 更新缓存」、「更新数据库 + 删除缓存」
3. 更新数据库 + 更新缓存方案,在「并发」场景下无法保证缓存和数据一致性,解决方案是加「分布锁」,但这种方案存在「缓存资源浪费」和「机器性能浪费」的情况
4. 采用「先删除缓存,再更新数据库」方案,在「并发」场景下依旧有不一致问题,解决方案是「延迟双删」,但这个延迟时间很难评估
5. 采用「先更新数据库,再删除缓存」方案,为了保证两步都成功执行,需配合「消息队列」或「订阅变更日志」的方案来做,本质是通过「重试」的方式保证数据最终一致
6. 采用「先更新数据库,再删除缓存」方案,「读写分离 + 主从库延迟」也会导致缓存和数据库不一致,缓解此问题的方案是「延迟双删」,凭借经验发送「延迟消息」到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率
# 四点心得
1. 性能和一致性不能同时满足,为了性能考虑,通常会采用「最终一致性」的方案
2. 掌握缓存和数据库一致性问题,核心问题有 3 点:缓存利用率、并发、缓存 + 数据库一起成功问题
3. 失败场景下要保证一致性,常见手段就是「重试」,同步重试会影响吞吐量,所以通常会采用异步重试的方案
4. 订阅变更日志的思想,本质是把权威数据源(例如 MySQL)当做 leader 副本,让其它异质系统(例如 Redis / Elasticsearch)成为它的 follower 副本,通过同步变更日志的方式,保证 leader 和 follower 之间保持一致