[MIT6.S081]Lab8: Locks
[MIT6.S081]Lab8: Locks
# [MIT6.S081]Lab8: Locks
Lab: locks (mit.edu) (opens new window)
# Memory allocator
这个 assignment 要我们改进内核的页面分配机制,本来是所有 cpu 共享一个空闲链表,然后对其上一把锁,现在我们改为给每一个 cpu 分配一个空闲链表,各自上一把锁,如果当前 cpu 的链表空间用完了再去借其他 cpu 的。
下面操作都在文件 kernel/kalloc.c 中进行
先将 kmem 变成数组类型
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NPROC];
在 kinit() 中我们初始化每个 kmem 的锁
void kinit() {
// initlock(&kmem.lock, "kmem");
for (int i = 0; i < NPROC; i++) {
initlock(&kmem[i].lock, "kmem");
}
freerange(end, (void*)PHYSTOP);
}
在释放的时候,也是先获取 cpuid 然后释放对应的空闲链表的空间
void kfree(void *pa) {
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off();
int c = cpuid();
pop_off();
acquire(&kmem[c].lock);
r->next = kmem[c].freelist;
kmem[c].freelist = r;
release(&kmem[c].lock);
}
需要注意的是 cpuid() 需要在中断关闭的时候使用,所以要先 push_off(),之后再用 pop_off() 打开。
而在 kalloc() 中,如果当前 cpu 的空闲链表用完了,则需要遍历其他的 cpu 来借空间,全程要记得上锁释放锁!
void * kalloc(void) {
struct run *r;
push_off();
int c = cpuid();
pop_off();
acquire(&kmem[c].lock);
r = kmem[c].freelist;
if(r) {
kmem[c].freelist = r->next;
}
release(&kmem[c].lock);
if (!r) { // 借其他 cpu 的空闲链表
for (int i = 0; i < NCPU; i++) {
if (i != c) {
acquire(&kmem[i].lock);
r = kmem[i].freelist;
if (r) {
kmem[i].freelist = r->next;
release(&kmem[i].lock);
break;
}
release(&kmem[i].lock);
}
}
}
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
# Buffer cache
在这个 assignment 中所有的 cpu 都共享着同一个 cache,为了避免单一的锁所带来的低性能,我们要修改这种 cache 的管理策略。
我们先给每块 buffer 都加了把锁,然后我们通过将不同 buffer 映射到一个哈希表上的各个桶中,通过对桶的锁管理,来降低锁的粒度,提高运行效率。
哈希表的长度 NBUCKET 选择素数 13,素数可以减小哈希冲突的可能,我们给每个桶分配了一段空闲的 buffer 链表,然后在查找 buffer 块的时候,根据 blockno 来将块映射到桶上。另外查找的过程中,如果它已经被 cache 了,那么我们直接可以 get 到。如果他没有被 cache,那么我们就要给它分配一个空闲块进行 cache,有分配那就有分配完的一天,也就会有替换操作,在我们选择被替换的 buffer 块时,我们要采用选择 LRU(Least Recently Used)策略。
首先我们要在 struct buf 中加入时间戳变量
// buf.h
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
uint ticks; // 时间戳
};
接着我们回到 bio.c 中开始实现
我们先宏定义一下哈希表的长度以及定义一下哈希表数组,并且声明一下 trap.c 中的 ticks,另外还要将单个锁都定义为数组形式
#define NBUCKET 13
extern uint ticks; // 声明外部变量 (trap.c 中的 ticks)
struct {
struct spinlock lock[NBUCKET]; // 桶锁
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head[NBUCKET];
} bcache;
int hash(int x) {
return x % NBUCKET;
}
对应的从单个锁变成了每个块和桶都有把锁,我们在 binit() 中也要全部初始化。
另外为了方便,我们一开始将所有的空闲 buffer 全都连在了哈希表的首位后面。
void binit(void) {
struct buf *b;
// 初始化哈希表的桶锁
for (int i = 0; i < NBUCKET; i++) {
initlock(&bcache.lock[i], "bcache");
}
// 初始化每块 buffer 的锁,并且双向链表变为单向链表,初始时全都接在 bcache.head[0] 后面
bcache.head[0].next = &bcache.buf[0];
for (int i = 0; i < NBUF - 1; i++) {
b = &bcache.buf[i];
b->next = b + 1;
initsleeplock(&b->lock, "buffer");
}
}
在实现获取 buffer 块 bget() 之前,我们先要实现函数 replace_cache 用来更新 cache 的值
void replace_cache(struct buf *b, uint dev, uint blockno) {
b->dev = dev;
b->blockno = blockno;
b->refcnt = 1; // 引用计数设置为 1
b->valid = 0;
}
接下来开始实现 bget()
【在实现这个函数的时候 当块没有被 cache 的情况参考了MIT 6.s081 xv6-lab8-lock - 知乎 (zhihu.com) (opens new window)】
首先我们先要获取 buffer 块对应的哈希值,以找到对应的桶,接着考虑如果这个 buffer 块已经被 cache 的情况
struct buf *b;
int hashid = hash(blockno); // 获取哈希值,看看映射到哪个桶
acquire(&bcache.lock[hashid]); // 获取这个桶的锁
// Is the block already cached? 该 block 已经被 cached 了的情况
for(b = bcache.head[hashid].next; b; b = b->next){ // 单向链表遍历
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock[hashid]); // 返回前释放这个桶的锁
acquiresleep(&b->lock); // 获取这个 buffer 的锁
return b;
}
}
接着考虑没有被 cache 的情况,先看看当前映射到的桶中是否有空闲块
// 如果该 block 没有被 cache
// 1. 查找当前桶中是否有空闲块
for (b = bcache.head[hashid].next; b; b = b->next) {
if (b->refcnt == 0) { // 是一个空闲块
replace_cache(b, dev, blockno);
release(&bcache.lock[hashid]);
acquiresleep(&b->lock);
return b;
}
}
然后我们查找其他桶中是否有空闲块,
// 2. 查找其他桶中是否有空闲块,并且选择 LRU
int bucket_id = -1; // 当前选中的空闲块所在的桶编号
struct buf *pre;
struct buf *take_buf = 0;
struct buf *last_take = 0;
uint time = __UINT32_MAX__;
for (int i = 0; i < NBUCKET; i++) { // 遍历所有桶
if (i == hashid) continue;
acquire(&bcache.lock[i]); // 获取当前桶的锁
for (b = bcache.head[i].next, pre = &bcache.head[i]; b; b = b->next, pre = pre->next) { // 遍历这个桶拥有的空闲块
if (b->refcnt == 0 && b->ticks < time) { // 如果是空闲块,并且上次使用的时间更早
time = b->ticks; // 更新时间戳
last_take = pre; // 记录一下当前位置前一个块的为主子
take_buf = b; // 目前选中的空闲块
if (bucket_id != -1 && bucket_id != i && holding(&bcache.lock[bucket_id])) { // 如果前一个选中的块不在当前的桶中,则释放前一个块锁持有的桶锁
release(&bcache.lock[bucket_id]);
}
bucket_id = i; // 更新桶编号
}
}
if (bucket_id != i) { // 如果没有用到这个桶,则释放桶锁
release(&bcache.lock[i]);
}
}
if (!take_buf) { // 没有找到空闲块
panic("bget: no buffers");
}
在我们找到目标块之后,我们要将他移到当前映射到的桶中,具体的方法其实就是链表的增删,还是比较简单的。
replace_cache(take_buf, dev, blockno); // 写 cache
last_take->next = take_buf->next; // 链表中删除选中的空闲块
take_buf->next = 0;
release(&bcache.lock[bucket_id]);
release(&bcache.lock[hashid]);
for (b = &bcache.head[hashid]; b->next; b = b->next); // 获取映射到的桶的最后一项
b->next = take_buf; // 移到最后面
acquiresleep(&take_buf->lock);
return take_buf;
最后我们还要修改一下 brelse()、bpin、bunpin() 中的锁,同时在释放块后,如果引用计数为 0 了,我们要更新他的时间戳。
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int hashid = hash(b->blockno);
acquire(&bcache.lock[hashid]);
b->refcnt--;
if (b->refcnt == 0) {
b->ticks = ticks;
}
release(&bcache.lock[hashid]);
}
void bpin(struct buf *b) {
int hashid = hash(b->blockno);
acquire(&bcache.lock[hashid]);
b->refcnt++;
release(&bcache.lock[hashid]);
}
void bunpin(struct buf *b) {
int hashid = hash(b->blockno);
acquire(&bcache.lock[hashid]);
b->refcnt--;
release(&bcache.lock[hashid]);
}
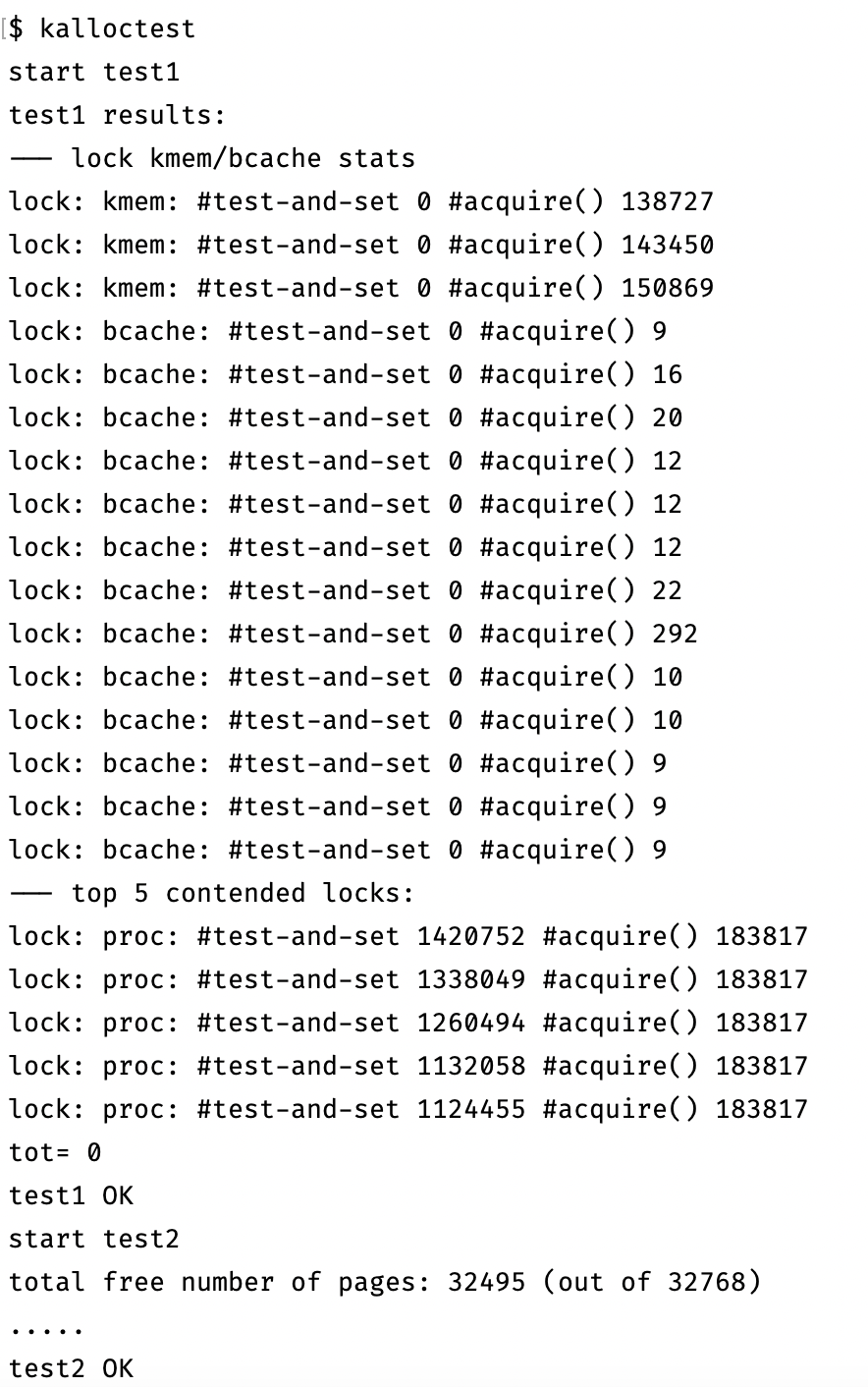
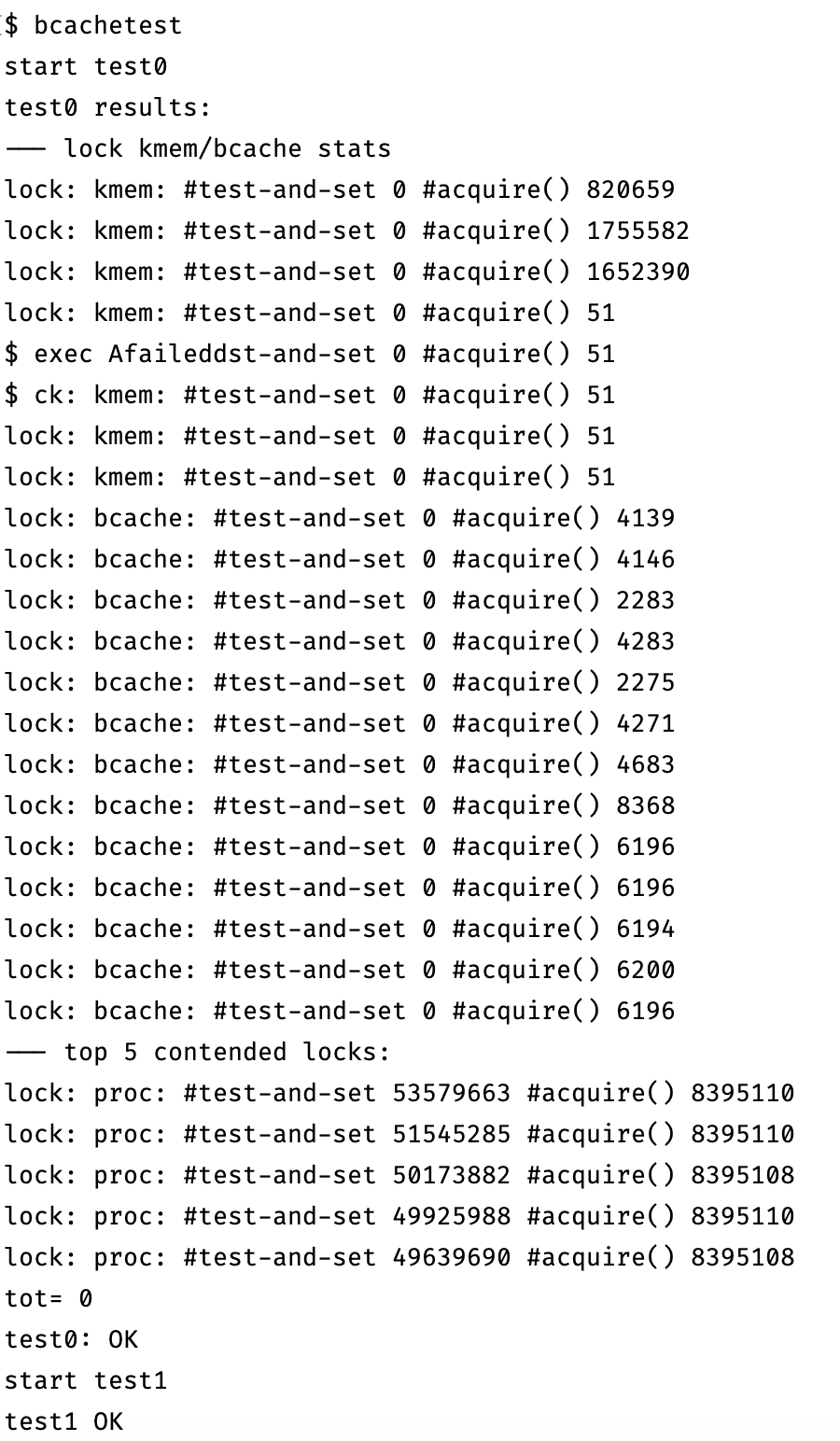
# 实验结果